L’optimisation des opérations entreprise ne consiste pas à empiler des outils plus modernes sur des flux mal compris. Elle consiste à rendre le travail visible, fiable et mesurable : qui fait quoi, avec quelles données, dans quel outil, à quel moment, avec quel niveau de contrôle. Takora intervient sur les opérations et la production lorsque la croissance ou la complexité font échouer les outils génériques : données fragmentées, process critiques encore manuels, peu de visibilité temps réel, et marges de manœuvre trop faibles pour scaler sans casser la qualité.
L'essentiel
- Le sujet n’est pas de tout automatiser : il faut d’abord identifier les flux qui créent le plus de risque, de lenteur ou de dépendance humaine.
- Les bons chantiers ops commencent souvent par une source de vérité claire, des responsabilités explicites et quelques intégrations fiables entre outils existants.
- L’IA peut aider sur certains cas précis, comme l’extraction, le routage ou le contrôle qualité, mais elle ne compense pas des données incohérentes ou un processus flou.
L’optimisation des opérations entreprise commence par le point de rupture
Dans beaucoup de PME et d’ETI, les opérations tiennent longtemps grâce à des personnes très compétentes qui connaissent les exceptions par cœur. Ce fonctionnement peut être efficace au début. Il devient fragile lorsque les volumes augmentent, que les responsabilités se répartissent entre plusieurs équipes ou que les outils ne reflètent plus la réalité du terrain.
Le vrai signal d’alerte n’est pas toujours un retard visible. C’est souvent une fatigue de coordination : un reporting préparé à la main chaque vendredi, un fichier Excel qui sert de vérité officieuse, une commande qui traverse trois outils sans identifiant commun, un responsable ops qui doit arbitrer des exceptions que le système devrait déjà qualifier.
Dans ce contexte, acheter un nouvel outil peut soulager un symptôme, mais pas forcément le système. Le premier travail est plus brutal : cartographier le flux réel, identifier où l’information se dégrade, puis décider si le problème relève d’une automatisation, d’une intégration, d’une donnée maître, d’un outil métier interne ou simplement d’une règle de gestion mieux formulée.
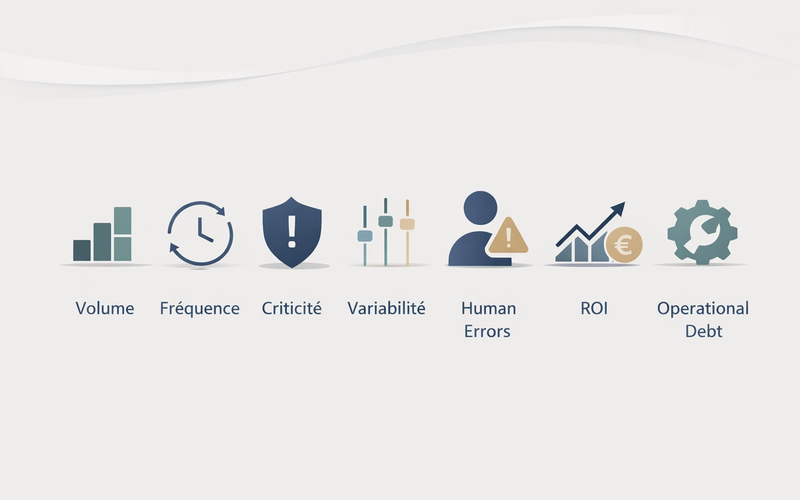
Les quatre signaux qui indiquent que vos opérations arrivent à saturation
Les symptômes opérationnels sont rarement isolés. Des données dispersées créent du contrôle manuel. Le contrôle manuel ralentit le reporting. Le reporting tardif masque les goulets d’étranglement. Et quand l’entreprise recrute ou augmente ses volumes, les mêmes faiblesses coûtent beaucoup plus cher.
| Signal observé | Ce que cela révèle souvent | Réponse prioritaire |
|---|---|---|
| Données éparpillées entre plusieurs outils | Chaque équipe possède une partie de la vérité, mais personne ne voit le cycle complet. | Définir la donnée maître, les règles de synchronisation et les identifiants communs. |
| Processus manuels chronophages et risqués | Les équipes compensent les limites du système par de la ressaisie, des copier-coller ou des contrôles informels. | Automatiser les étapes stables, garder l’humain sur les exceptions et documenter les contrôles. |
| Manque de visibilité sur les opérations | Les décisions se prennent avec des indicateurs tardifs, incomplets ou reconstruits manuellement. | Créer un pilotage fiable : statuts, événements, délais, volumes, alertes et propriétaires. |
| Difficultés de scaling opérationnel | Chaque hausse d’activité exige presque autant d’effort humain supplémentaire. | Standardiser les flux critiques, intégrer les outils et isoler les cas particuliers. |
Cette lecture évite une erreur fréquente : confondre volume de tâches et complexité opérationnelle. Une tâche répétitive peut être simple à automatiser. Un flux qui traverse plusieurs équipes, plusieurs outils et plusieurs règles métier nécessite d’abord une architecture plus propre.
Automatiser, intégrer ou refondre : comment choisir sans lancer un chantier trop lourd ?
Trois réponses reviennent souvent : automatiser un geste, connecter des outils ou développer un outil métier. Aucune n’est supérieure par principe. Le bon choix dépend de la stabilité du processus, de la qualité des données, du risque d’erreur et de la fréquence des exceptions.
| Option | Quand c’est pertinent | Quand c’est risqué |
|---|---|---|
| Automatisation | Le flux est stable, répétitif, bien compris et les règles sont explicites. | Le processus change chaque semaine ou dépend d’un jugement humain non formalisé. |
| Intégration | Les bons outils existent déjà, mais les données circulent mal entre eux. | Chaque outil utilise des statuts, identifiants ou règles incompatibles sans arbitrage métier. |
| Logiciel sur mesure | Le processus est différenciant, mal couvert par les SaaS et critique pour la qualité ou la marge. | L’équipe cherche à reconstruire un ERP entier sans avoir isolé le périmètre utile. |
| Refonte organisationnelle légère | Le problème vient surtout de responsabilités floues ou de règles non décidées. | On tente de corriger un désalignement humain uniquement par du code. |
Le piège classique est le big bang : vouloir remplacer tout le système au lieu de traiter un flux prioritaire. Dans une organisation déjà sous tension, un grand projet mal cadré ajoute de la charge avant de produire de la valeur. Une approche plus saine consiste à choisir un processus, mesurer ses frictions, corriger les données et connecter seulement ce qui doit vraiment l’être.
Données et fiabilité avant plus d’IA
L’IA peut être très utile dans les opérations, mais seulement lorsqu’elle est placée au bon endroit. Elle peut aider à extraire des informations d’un document, préqualifier une demande, router un ticket, détecter une anomalie ou assister un contrôle qualité. Elle devient dangereuse lorsqu’on lui demande de masquer l’absence de règles, de corriger des données incohérentes ou de prendre des décisions métier sans traçabilité.
Avant d’ajouter de l’IA, il faut répondre à des questions simples : quelle donnée fait foi ? Quel événement déclenche l’étape suivante ? Qui valide les exceptions ? Comment vérifie-t-on qu’une décision automatique est correcte ? Que se passe-t-il lorsque le modèle est incertain ? Ces questions sont moins séduisantes qu’une démonstration IA, mais elles déterminent si le système tiendra en production.
Une bonne architecture ops accepte donc deux réalités. D’un côté, certains gestes doivent disparaître parce qu’ils sont répétitifs et sources d’erreur. De l’autre, certains contrôles doivent rester humains, mais mieux outillés : avec les bonnes données, les bons statuts et les bonnes alertes.
Exemple réaliste : une PME industrielle qui ne voit plus ses retards à temps
Prenons une PME industrielle qui vend à des distributeurs. Les commandes arrivent dans un CRM, la disponibilité produit est suivie dans un ERP, les ajustements logistiques passent par e-mail et le reporting hebdomadaire est consolidé dans un fichier partagé. Tant que le volume reste modéré, l’équipe compense. Quand les commandes augmentent, les retards sont détectés trop tard, les stocks sont interprétés différemment selon les équipes et les clients reçoivent des réponses incohérentes.
Le premier réflexe pourrait être de chercher un nouvel ERP. Ce serait peut-être utile un jour, mais pas forcément le bon premier pas. Un diagnostic plus pragmatique peut montrer que le vrai point de rupture se situe entre la commande validée, le stock disponible et la promesse de livraison. La réponse initiale peut alors être plus légère : aligner les statuts, créer un identifiant commun de commande, automatiser la mise à jour de disponibilité, envoyer des alertes en cas d’écart et produire un tableau de pilotage quotidien.
Ce mini-cas n’est pas spectaculaire, et c’est précisément l’intérêt. L’amélioration opérationnelle sérieuse ressemble rarement à une révolution visible. Elle ressemble plutôt à moins de ressaisie, moins de zones grises, moins de dépendance à une personne clé et plus de décisions prises sur des données fiables.
La méthode de lecture Takora : diagnostic, gains rapides, architecture évolutive
Une intervention utile sur les opérations doit éviter deux excès : rester au niveau du conseil théorique ou partir trop vite en développement. Le rôle d’un partenaire technique sérieux est de traduire un problème opérationnel en décisions concrètes : données, flux, responsabilités, outils, risques et séquencement.
Un enchaînement raisonnable pour traiter un flux critique
1. Cartographier le flux réel
Observer les étapes telles qu’elles se passent vraiment, y compris les contournements, fichiers parallèles et validations informelles.
2. Identifier la donnée qui fait foi
Décider quelle source porte les statuts, les identifiants, les montants, les délais et les événements critiques.
3. Supprimer les gestes sans valeur
Automatiser les ressaisies et notifications stables, sans retirer le contrôle humain là où il est encore nécessaire.
4. Connecter les outils utiles
Créer des intégrations fiables entre les systèmes existants plutôt que remplacer toute la stack par réflexe.
5. Mesurer et durcir
Suivre les délais, erreurs, volumes et exceptions pour fiabiliser le système avant d’étendre le périmètre.
Ce séquencement permet de créer de la valeur sans bloquer l’activité. Il donne aussi une base saine si l’entreprise décide ensuite de développer un outil métier plus structurant ou de remplacer une partie de sa stack.
Erreurs fréquentes dans les chantiers opérations et production
- Automatiser un processus instable avant d’avoir clarifié les règles métier.
- Créer un tableau de bord sans corriger les données qui l’alimentent.
- Multiplier les outils SaaS sans décider quelle source fait autorité.
- Transformer chaque exception en fonctionnalité au lieu de standardiser le cas nominal.
- Confondre vitesse de développement et fiabilité en production.
- Lancer une refonte complète alors qu’un flux prioritaire suffirait à valider l’approche.
Il faut aussi savoir quand ne pas investir. Si le volume est faible, si le processus change tous les mois, si l’équipe n’a pas encore tranché les règles de décision ou si les données de base ne sont pas maintenues, un développement ambitieux créera probablement plus de dette que de valeur. Dans ce cas, le meilleur investissement est souvent une clarification métier courte, suivie d’un prototype limité.
Comment structurer vos opérations sans tout refaire ?
Le point de départ le plus fiable est de choisir un flux à fort effet de levier : commande, onboarding, approvisionnement, planification, contrôle qualité, facturation, support interne ou reporting de production. Le flux doit être assez important pour justifier l’effort, mais assez limité pour être compris en quelques ateliers.
- Nommer un propriétaire métier du flux.
- Lister les outils, fichiers et canaux réellement utilisés.
- Identifier la donnée maître et les doublons critiques.
- Mesurer les délais, erreurs, ressaisies et exceptions.
- Classer les actions possibles : règle métier, automatisation, intégration, outil interne ou abandon.
- Livrer un premier gain observable avant d’élargir le périmètre.
Cette discipline évite de transformer un problème opérationnel en projet informatique abstrait. Elle oblige à relier chaque décision technique à un résultat observable : moins d’erreurs, moins de temps perdu, meilleure visibilité, meilleure qualité de service ou capacité à absorber plus de volume sans recruter dans la même proportion.
FAQ — opérations, production et scaling
01 Faut-il remplacer Excel s’il est encore partout dans nos opérations ?
02 Combien de temps faut-il pour obtenir un premier gain opérationnel ?
03 Quand un logiciel sur mesure est-il préférable à un outil SaaS ?
04 L’IA peut-elle résoudre un problème de productivité opérationnelle ?
05 Par où commencer si tout semble prioritaire ?
Conclusion : scaler les opérations, c’est réduire les zones grises
Une organisation ne devient pas plus scalable parce qu’elle ajoute un outil ou une couche d’IA. Elle le devient lorsque les flux critiques sont compris, les données fiables, les responsabilités explicites et les décisions traçables. C’est moins spectaculaire qu’une transformation digitale annoncée en grand, mais beaucoup plus solide.
Pour un dirigeant, un COO ou un responsable IT, la bonne question n’est donc pas seulement : quel outil devons-nous choisir ? Elle est plutôt : quel flux devons-nous rendre fiable en premier, et quel niveau de technologie est réellement nécessaire pour y arriver ?
À retenir
- Ne commencez pas par la solution : commencez par le flux qui casse.
- Cherchez la donnée qui fait foi avant d’automatiser.
- Privilégiez les intégrations et quick wins fiables avant une refonte lourde.
- Utilisez l’IA seulement lorsque le processus, les données et les contrôles sont assez clairs pour la mettre en production.
Takora peut analyser un flux critique, identifier les ruptures de données ou de responsabilité, puis recommander le bon arbitrage entre automatisation, intégration et développement sur mesure.
Pour aller plus loin
Ressources complémentaires
Sources
Références et documentation